Token Optimization that just works
Compress prompts in real time and reduce your AI spend by up to 60% with identical output quality
How TwoTrim Saves You Money

Intelligent Prompt Compression
Preserves meaning perfectly • Works with any LLM
Real-Time Optimization
Zero latency overhead • Stateless architecture • Drop-in replacement
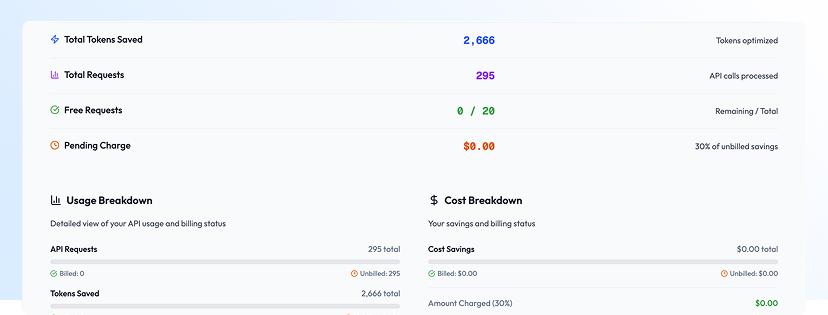
Transparent Dashboard
Track every dollar saved • Detailed analytics • Export reports

Enterprise Security
Zero data logging • SOC 2 compliant • On-premise available
Your Data Never Leaves Your Control
We never store your prompts, responses, or any metadata. For maximum security, we offer on-premise deployment options for enterprise customers.
Prompts and responses never stored. Complete data privacy.
Data discarded after optimization. No persistent storage.
Deploy TwoTrim in your own infrastructure for maximum control.
The Science Behind the Savings
Our proprietary algorithms analyze prompt structure, context, and intent to achieve maximum compression while preserving semantic meaning
Semantic Preservation
Maintains exact meaning and context
Context-Aware Compression
Understands prompt intent and structure
Multi-Model Optimization
Works with GPT-4, Claude, Gemini, and more
Real-Time Processing
<30ms overhead per request
Loved by Engineering Teams
"We slashed token waste without touching a single prompt. TwoTrim paid for itself in days."

